Simple Pose Estimation with Hourglass Model
Pose Estimation seemed an interesting idea for me to explore and implement after my previous project, which was fast style transfer.
I searched around for the latest literature regarding this and came across the Hourglass model, implemented by Alejandro Newell et al. I read the paper and found the results fascinating since it managed to do a pretty job of detecting different joints in the human body. Then I searched for a Tensorflow implementation and came across Walid Benbihi's Github implementation. The dataset text file available in his project was especially useful since it was a dictionary of the MPII image dataset. This dictionary contained image names along with the other useful coordinate data for the joints in an easy-to-parse format. MPII does provide this data on their website but this dictionary was easier to work with.
I was definitely interested now but the hourglass model seemed a bit complex and wondered if there was a simpler way to detect pose. I wondered if YOLO could work in this situation. I'd intended to mark my body joints with a 32x32 or even a 64x64 box. After I read the paper, I wasn't sure how well it would work since they said the model doesn't work too well for small objects. But hey, don't knock it till you try it, right?
I spent the next couple of days poring over the paper and doing my best to understand the loss function. I did find a YOLO implementation on Walid's github (in the same hourglass project) that helped me make sense of the model and the loss function. The coordinates squared error was simple enough. The object and no-object loss was a bit harder to understand but I managed to push through.
Next, I pre-processed the MPII dataset and pushed the data, including the images and the coordinate data into an hdf5 file (to prevent data input throttling). Then I re-wrote the YOLO model I'd found previously and trained it on the dataset.
My observations after completing the training and testing:
- YOLO did not work well for joint detection and hence pose detection. It was somewhat decent at detecting the pelvis and the top of the head but was bad at other joints. This confirmed the paper's findings that it was bad at small objects.
- The training schedule was spot on, as described by the paper. You needed to train at a certain learning rate for certain epochs and then drop it down because the loss went to 'nan'.
- After initial training on the default sized YOLO network as described in the paper, I looked at the predictions to see if it worked. Turns out that no matter what I gave as input, I got the same predictions! The answers here helped a lot in understanding the issue. Either the network was too big because of which the backpropagated signal tended to die down, or the data and the labels don't match each other well.
- To see if a smaller network helped, the authors mentioned a smaller YOLO network and I found an implementation here. Training on this network did do a 'better' job of giving different predictions for different inputs but the predictions were bad regardless.
- Perhaps a residual network could help? I added some skip connections in the smaller network to see if that would help but that didn't help either.
In conclusion, it seemed to me that YOLO was not a good fit for pose estimation. Either that or modifications of some sort was required for either the model or the data to make it work with respect to this task.
After that failed foray (I did learn a lot so not a complete loss!), I decided to finally try the hourglass model.
But with a twist.
The ground truth inputs in the original implementation were 16 Gaussian kernels (for each image, one per joint) centered on the joint. If there were multiple people in the image, a separate set of inputs were developed per person. The network then gave 1 prediction for each joint (16 total). The network loss was simply the mean squared error between the inputs and the predictions.
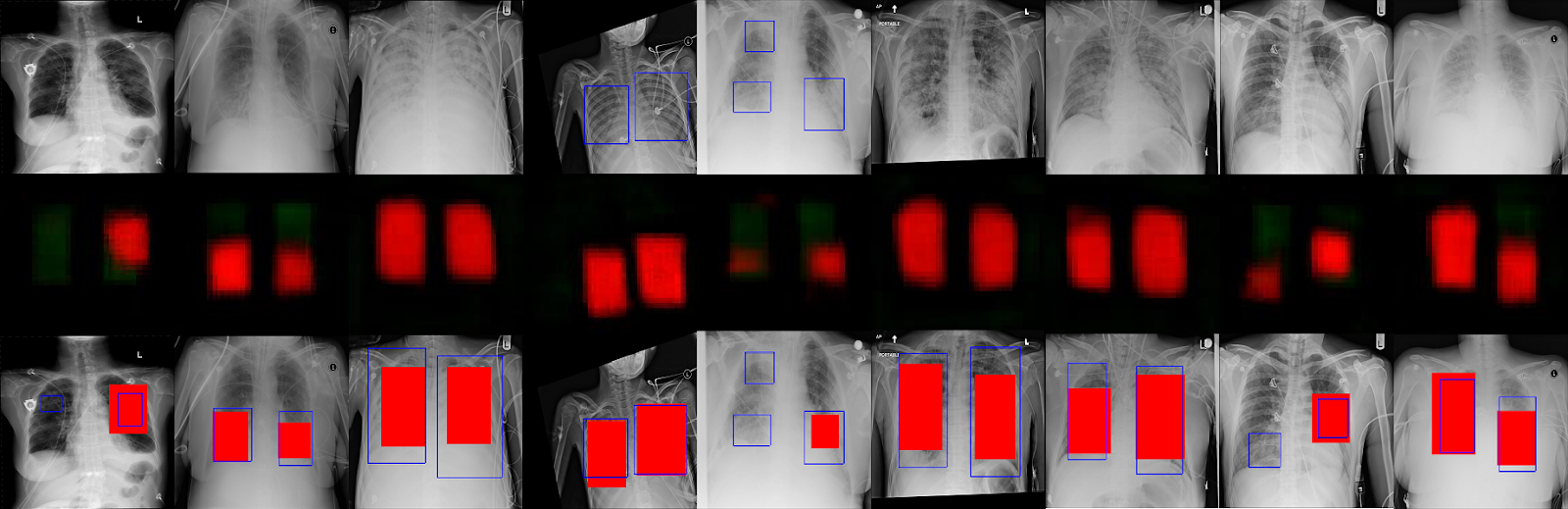
My idea was to provide the pose itself as a ground truth input for the image. The legs would be colored red, the torso green and the hands blue. In essence, instead of a 16 dimensional prediction, the output would be 3 dimensional (R,G and B). The background would be completely black ,essentially telling the network to ignore the background and focus on the person. An example:

In this case as well, the network loss would be mean squared error between the predictions and the ground truth input.
I decided to give this a shot and implement the model. Parameters of the network are as follows:
- Learning rate of 2.5e-4
- 60 epochs
- 4 stacks of the hourglass unit
- Batch size of 16
- 90% of the dataset for training, rest for testing
- 256 filters at every convolution step (unless mentioned otherwise)
- No intermediate supervision (details in the paper)
- No data augmentation
Training this over the 90% of the dataset took 17 hours (approx. 1000 secs per epoch)
I haven't used any hard metrics to measure accuracy. This was a purely subjective experiment to see how well the model and the unique ground truth representation worked.
Below are the results of the inference.

I also used a webcam to record and infer some poses in real time. I saved each frame and converted the set of those images into a gif. Below are the results.


I haven't used any hard metrics to measure accuracy. This was a purely subjective experiment to see how well the model and the unique ground truth representation worked.
Below are the results of the inference.
I also used a webcam to record and infer some poses in real time. I saved each frame and converted the set of those images into a gif. Below are the results.

Some notes on the results:
- If there are multiple people in the scene, the predicted pose does predict poses for each of them but not always. It did its job in the first and the sixth image. There are multiple people in the 2nd, 3rd and 4th image but it predicted pose for only one person.
- In most of the inferences, the torso was detected the best.
- A well lit, facing the camera type of image usually gave the best results.
- Some of the more unique poses, like the last 2, were somewhat difficult for the network to predict. In the last one, it mistook the left hand for a leg.
- I think more data involving unique poses should take care of the above issue.
- The real time inferences weren't great with the leg poses. The torso again, had the best detection.
Changes that could improve the results:
- Data augmentation
- Intermediate supervision
- Larger model of 8 or more stacks (though that requires a much larger VRAM)
- Training for more epochs
Code can be found here: https://github.com/varunvprabhu/simple_pose_hourglass

Comments
Post a Comment